Motivating scenario: You have some data of a single numeric variable. Before running any formal tests, you need to get to visualize and summarize the data!
Learning goals: By the end of this section, you should be able to:
Calculate the mean and standard deviation for a sample in R.
Define, calculate, and interpret Cohen’s D as a standardized measure of effect size for a one-sample test.
Create a histogram using ggplot2 to visualize the distribution of a sample.
Use summary statistics and a histogram to provide a preliminary, descriptive answer to a research question.
We have previously considered standard summaries of univariate data. Because the \(t\)-distribution assumes a normal distribution, we focus on standard parametric estimates. These include:
The mean: A measure of central tendency, \(\bar{x} = \frac{\Sigma x_i}{n}\).
The standard deviation: A measure of central spread, \(s = \frac{\Sigma(x_1-\bar{x})^2}{n-1}\).
Cohen’s D: A standardized measure of effect size, \(D = \frac{\bar{x}-\mu_0}{s}\).
We introduced Cohen’s D in the associations section, but can be used for a single numeric variable as well!
I calculate these below:
Summarizing range shift data
mean
sd
cohens_d
39.33
30.66
1.28
# set null to zeromu_0 <-0# summarize datarange_shift_summary <- range_shift |>summarise(mean =mean(elevationalRangeShift),sd =sd(elevationalRangeShift),cohens_d = (mean - mu_0) / sd)
As a reminder
Cohen’s D between 0.50 and 0.80 is considered a “medium” effect.
Cohen’s D between 0.80 and 1.20 is considered a “large” effect.
Cohen’s D between 1.20 and 2.00 is considered a “very large” effect.
So, our observed Cohen’s D of 1.28 means that this effect is quite strong!
Data visualization
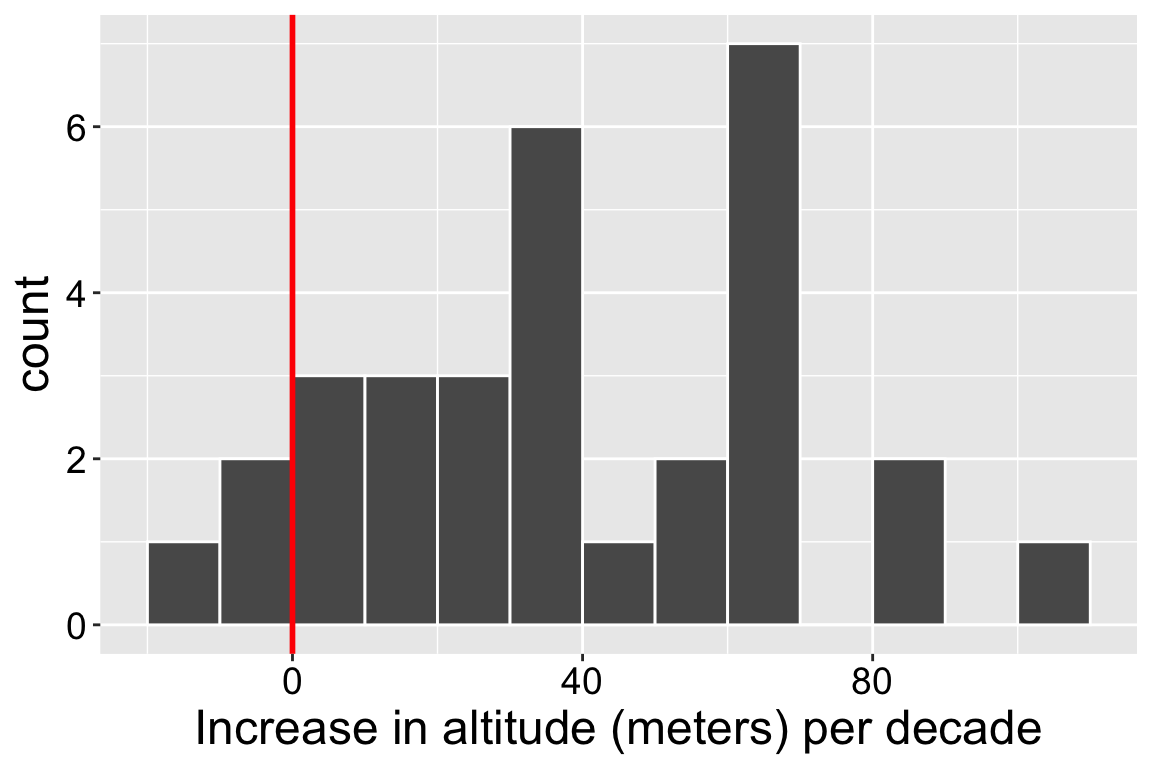
We will develop a few visualizations of our data. For now, I present a simple histogram. Figure 1, clearly shows that most species have moved uphill. It also allows us to evaluate if the data are normalish, as assumed by the t distribution. We spend the next section thinking harder about assumptions of the t distribution, and if our data.
Figure 1: A histogram showing the distribution of observed elevational range shifts (in meters per decade) for 30 taxonomic groups. The vertical red line indicates a shift of zero, the value specified by the null hypothesis. Data from Chen et al. (2011).
Chen, I.-C., Hill, J. K., Ohlemüller, R., Roy, D. B., & Thomas, C. D. (2011). Rapid range shifts of species associated with high levels of climate warming. Science, 333(6045), 1024–1026. https://doi.org/10.1126/science.1206432